I’ve just listened to the latest episode of Alastair and Andrew‘s podcast, scene from above, and the discussion section based around near-future predictions for the Earth Observation (EO) industry, as well as some of the discussion in the news section, was extremely interesting. I’m fully onboard the hype train for machine learning booming in EO, with Andrew seemingly somewhat skeptical.
Before I go into why I think that’s the case, I’ll mention Alastair speaks about a Voyager documentary, the Farthest (I’ve actually just noticed a big Irish producer, crossing the line was involved in production, wahay!). It sounds absolutely incredible, and will go on my watch list, but Alastair’s comments reminded me of an xkcd comic alluding to the fact that the edge of the solar system is difficult to define! I actually really enjoyed listening to their thoughts on Voyager in general, and would love to hear more discussion around the history of EO as well as wider planetary missions – every time I read and think about Corona, for example, I can’t help but be amazed.

Voyager spacecraft (NASA)
One of the main predictions made within the main section of the podcast is that analysis ready data (ARD) will see wider use and release by data providers. We have seen a move towards sentinel 2 ARD and planet have recently released their atmospherically corrected surface reflectance product, I would hope this is an indication that this is quite well developed already!
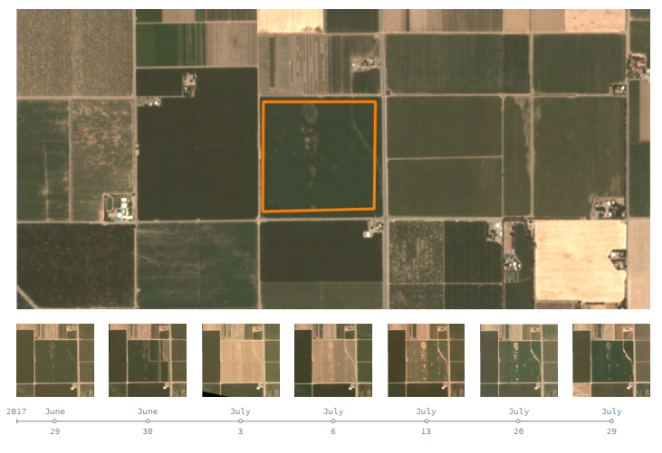
A figure from Planet’s surface reflectance white paper (source)
On the machine learning (ML) front, I attended a google earth engine workshop at the beginning of this year, and having had fruitful discussions with the host on the project’s directions, I think the iron is hot for ML and the hype justified. In particular, the host spoke about the team preparing tensor flow integration into the platform in time for AGU next year. Having been lucky enough to participate in (albeit not at a competitive level) the planet kaggle competition for classifying image excerpts into one or more classes last year, I have a decent idea of just why there has been a frenzy of research surrounding convolutional neural networks (CNNs) in the computer vision community, and I’m surprised that they haven’t appeared more in EO research.
While Andrew notes that supervised and unsupervised classification has been around and used for decades, the difference between those and deep-learned information is like night and day in my opinion. The competition, past the task presented, gave me a look into how neural networks are transforming image analysis, and how recurrent CNNs on massive scales could be leveraged in an environmental context for things like linking phenological mapping to data which might provide reasons as to why a change is happening with spatial context. Object-based analysis is unparalleled for applications like this, and CNNs are now so easy to use and much better at handling massive data sets than previous methods. Computer scientists are poised to integrate more and more with the EO community as higher resolution data becomes available, and so I feel like when high temporal and spatial resolution open data becomes available multi-disciplinary research will really kick off. Infact, I put together a starter ipython notebook for bird identification, showing just how easy it is using a pre-trained CNN for this application, albeit not with EO data.
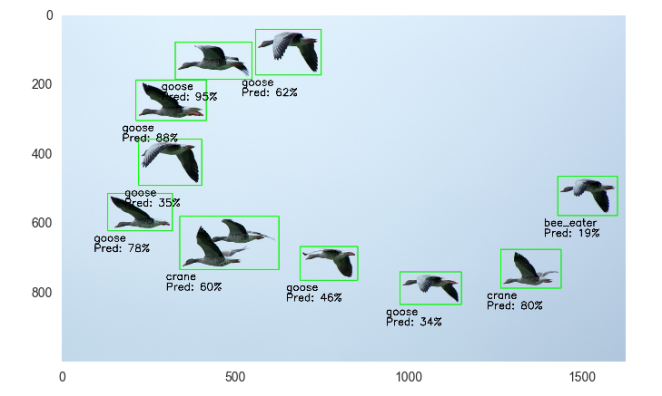
Example plot from ipython notebook
This leads to a prediction of my own – as more imaging scientists move into EO, Unmanned aerial vehicle (UAV) and satellite data will need to be better integrated. Currently, there are a raft of problems linking data collected from consumer level cameras onboard UAVs to satellite data, not least of which is radiometric normalization. The demand for higher resolution data from the deep learning end of the community will lead to new standards being introduced for how UAV data is collected and metadata stored (shameless plug). EO platforms will begin to integrate publicly collected UAV data and satellite researchers will begin to collaborate with computer scientists using nearer earth images. We will then see satellites being used as an early warning systems and UAV missions automatically launched off the back of satellite derived information in a range of new applications.
This isn’t a particularly insightful prediction, but one which continuously hasn’t really been addressed. I’m always surprised as to how infrequently satellite and UAV data are used in tandem, but I’m hoping this will change!
That’s all for now, look for my Google Earth Engine blog coming next week, I was blown away by the product and definitely need to do a separate post on it 🙂
















{kind=link}